

The classification is a type of supervised machine learning problem n which the algorithm learns to assign each observation to a class or category.
It is used to determine whether something belongs to group A or B (binary classification) or to multiple possible categories (multiclass classification). The complete dataset is used to create the model, and the evaluation metrics are generated using K-fold technique (cross-validation).
In a digital twin, ML classification model is useful for predicting states, operating conditions, part types, the occurrence of failures, or any scenario where the output is a discrete label.
Types of Classification Models
Classification algorithms can generally be grouped into three main types: binary, multiclass, and multilabel.
Binary classification solves problems with only two possible outcomes (e.g., yes/no, pass/fail).
Multiclass classification deals with selecting one label from more than two categories.
Multilabel classification allows assigning multiple labels to a single observation simultaneously.
These distinctions help define how a classification model is trained and evaluated, and they are essential for choosing the right approach in your machine learning development process.
Machine Learning Algorithms
Once the type of classification task is defined, the next step is selecting an appropriate algorithm to build the machine learning model. These algorithms are the mathematical engines that learn from data and make predictions. Some of the algorithms our digital twin platform TOKII includes are:
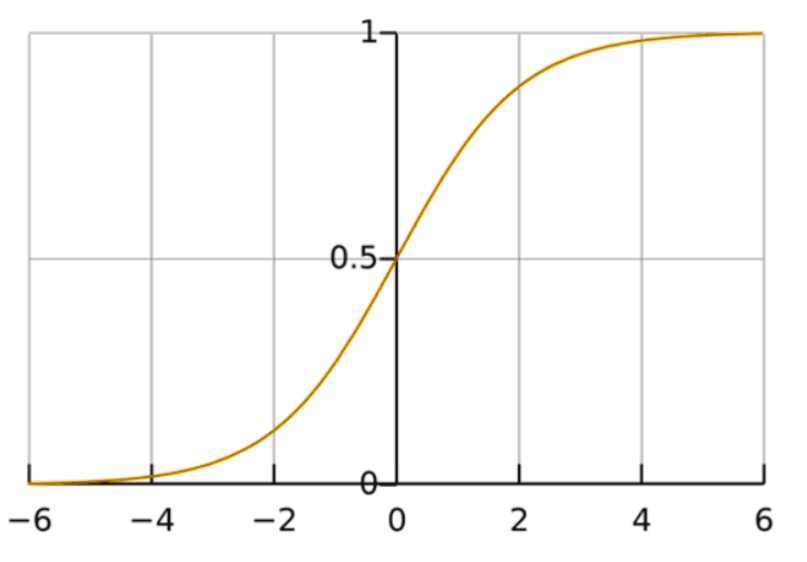
Logistic Regression
Logistic regression is a linear model that estimates the probability that a record belongs to a given class. Although its name contains the word “regression,” it is used exclusively for classification, especially binary classification.
It is suitable when the relationships between variables and classes are relatively simple or linear, or when you need a fast and stable model to start with. Use logistic regression when you want a fast, explainable model with a simple decision structure.
Decision Tree
A tree divides the dataset by applying rules of the type "if value X is greater than Y...". It builds a decision structure that allows classifying observations following a path from the root to a leaf.
It is useful when you expect non-linear relationships, when you have many variables of different types, or when you seek interpretability.
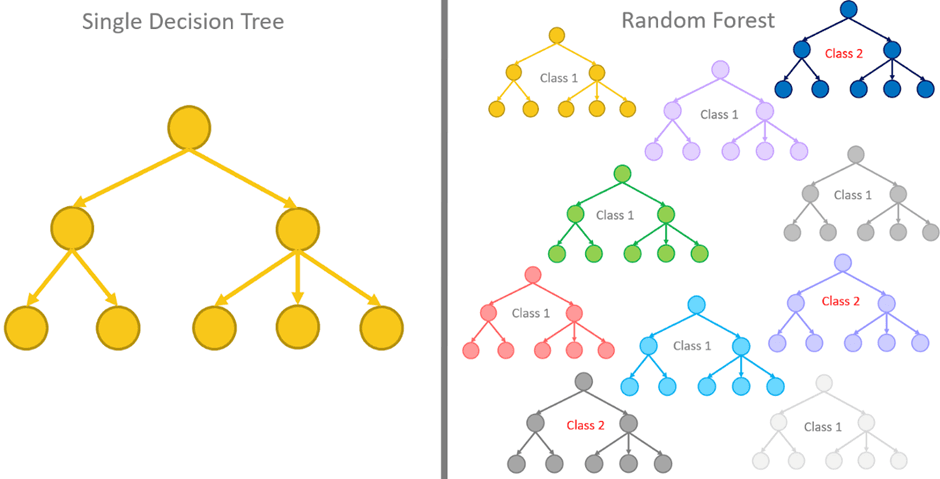
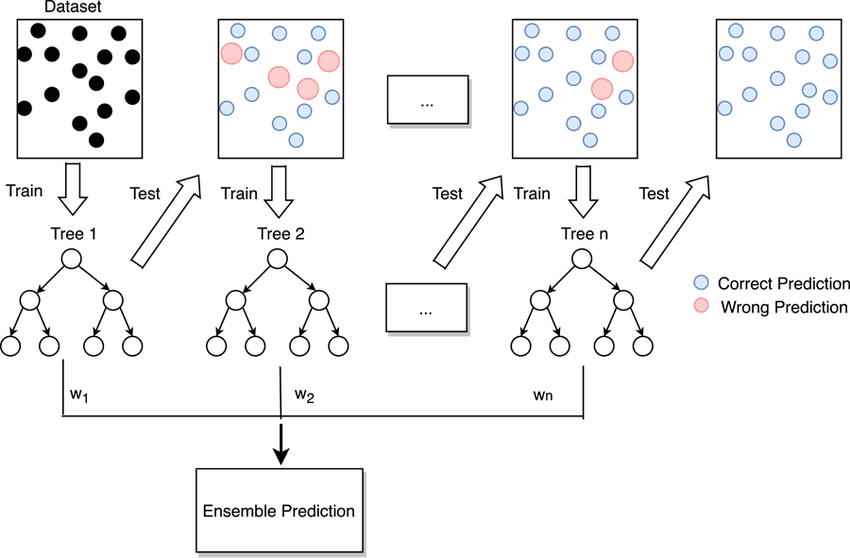
Random Forest
A decision tree splits the dataset using rules such as “if value X is greater than Y…”. It builds a decision structure that classifies observations by following a path from the root to a leaf.
It is useful when you expect nonlinear relationships, when you have many variables of different types, or when you need interpretability. It is a good algorithm when you need to understand the model’s logic or when your dataset mixes different types of variables.
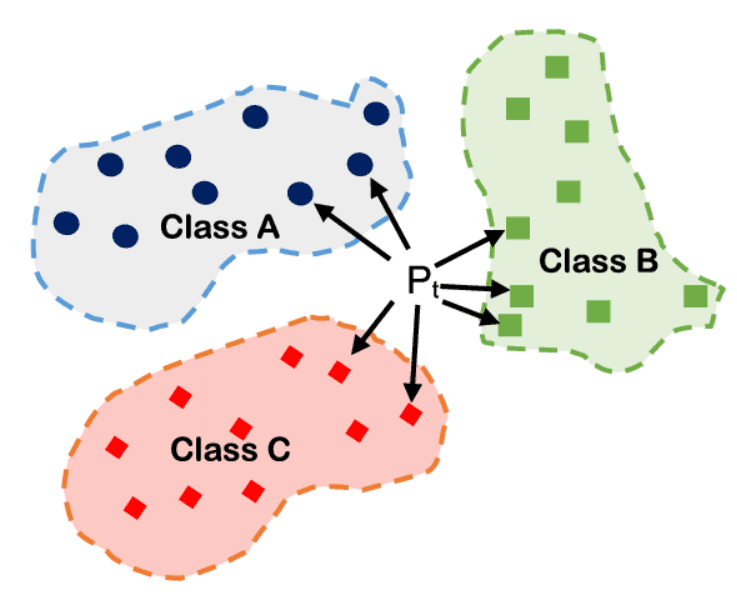
K-Nearest Neighbors (KNN)
KNN classifies a new observation by looking at the closest ones in the feature space. The majority class among those neighbors determines the prediction.
It is suitable when the data does not follow a clear decision boundary and classes are distributed across regions.
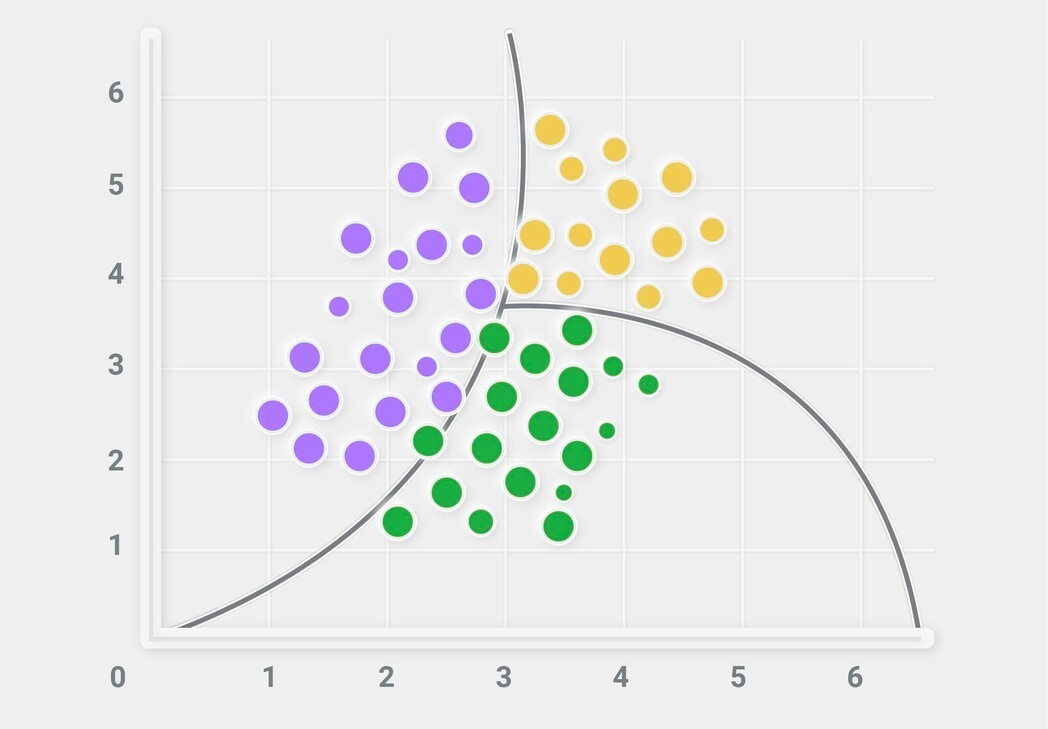
Naive Bayes (NBC)
Naive Bayes is a probabilistic classifier that assumes independence between variables.
It works particularly well in problems where individual features are frequent but weak (e.g., text, noisy sensors, frequency‑based inputs).
Gradient Boosting Classifier
A boosting model that builds trees sequentially, where each new tree corrects the errors of the previous one.
It is highly effective on datasets with complex relationships and often delivers high accuracy when carefully configured.
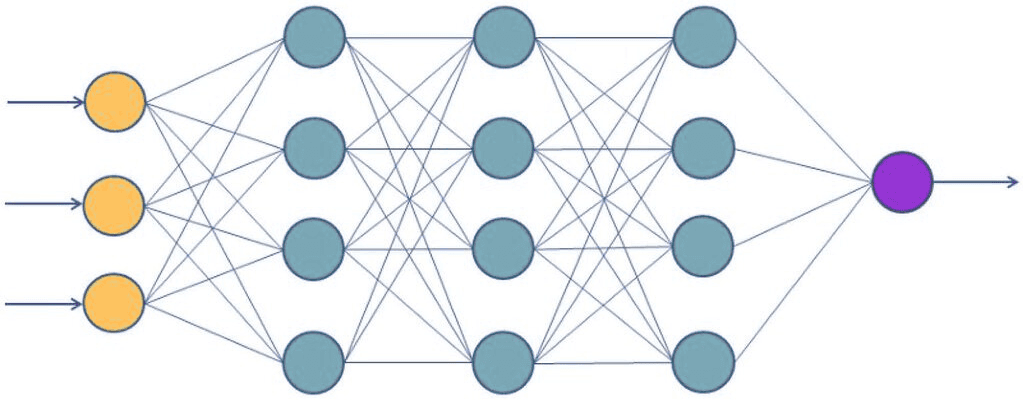
Neural Network (MLP Classifier)
A multilayer perceptron (MLP) is a model based on layers of artificial neurons capable of learning nonlinear relationships.
It is suitable when you have many observations or when patterns depend on complex combinations of variables.
How to Choose the Best Classification Model in Machine Learning - Tips from Our Experts
Normalize the data when using KNN, logistic regression, or neural networks.
Balance the classes if one category appears much more than another; it improves the quality of the model.
Start with simple models (logistic regression, tree) before using complex models.
Avoid very deep trees to not overfit.
Split the data into training and test with temporal coherence if the dataset represents industrial processes.
Do not use all advanced hyperparameters at first: adjust only the key ones according to the algorithm.
Evaluate metrics beyond accuracy when classes are unbalanced (F1, recall).
Classification is one of the algorithms used for predictive analytics without programming, and properly applying these techniques makes the difference between having data and getting value from it.
At IMMERSIA, we are specialists in data analysis and advanced visualization. If you want to learn how to apply these methodologies to help improve your processes, increase performance, and reduce costs, request a personalized DEMO, and our experts will guide you.


