

La clasificación es un tipo de problema de machine learning supervisado en el que el modelo aprende a asignar cada observación a una clase o categoría.
Sirve para determinar si algo pertenece al grupo A o B (clasificación binaria) o a varias categorías posibles (clasificación multiclase). Se usa el dataset completo para crear el modelo, y las métricas de evaluación se generan mediante la técnica K-fold (cross-validation).
En un gemelo digital, es útil para predecir estados de activos, condiciones operativas, tipo de pieza, aparición de fallos o cualquier escenario donde la salida es una etiqueta discreta.
Tipos de modelos de clasificación
Generalmente, los algoritmos de clasificación pueden agruparse en tres tipos principales: binarios, multiclase y multietiqueta.
Clasificación binaria: resuelve problemas con solo dos resultados posibles (por ejemplo, sí/no, aprobado/suspenso).
Clasificación multiclase: selecciona una etiqueta entre más de dos categorías.
Clasificación multietiqueta: permite asignar varias etiquetas a una misma observación de forma simultánea.
Estas distinciones ayudan a definir cómo se entrena y evalúa un modelo de clasificación, y son esenciales para elegir el enfoque adecuado en tu proceso de desarrollo de machine learning.
Algoritmos de machine learning
Una vez definido el tipo de tarea de clasificación, el siguiente paso es seleccionar el algoritmo apropiado para construir el modelo de machine learning. Estos algoritmos son los motores matemáticos que aprenden de los datos y realizan predicciones. Algunos de los algoritmos que incluye nuestra plataforma de gemelos digitales TOKII son:
Regresión Logística
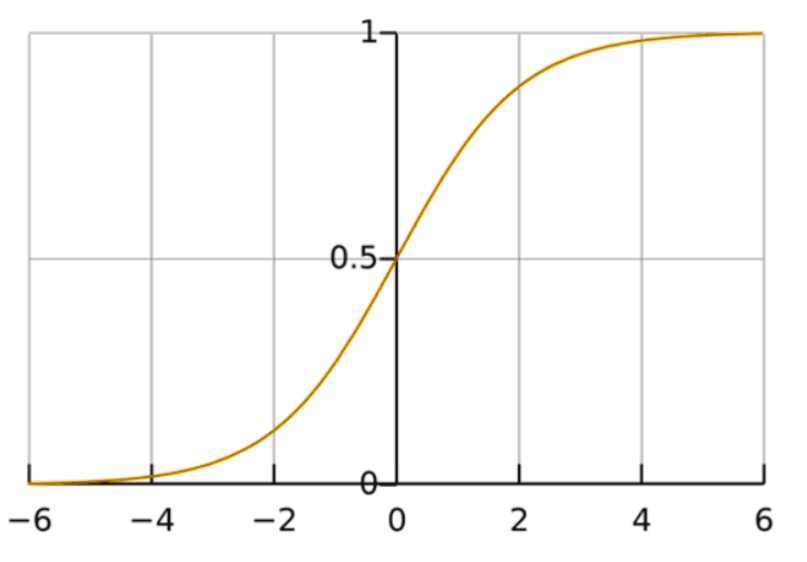
La regresión logística es un modelo lineal que estima la probabilidad de que un registro pertenezca a una clase. Aunque su nombre lleve “regresión”, se usa exclusivamente para clasificación, especialmente binaria.
Es adecuado cuando las relaciones entre variables y clases son relativamente simples o lineales, o cuando se quiere un modelo rápido y estable para empezar.
Árbol de Decisión
Un árbol divide el dataset aplicando reglas del tipo “si el valor X es mayor que Y…”. Construye una estructura de decisión que permite clasificar las observaciones siguiendo un recorrido desde la raíz a una hoja.
Es útil cuando esperas relaciones no lineales, cuando tienes muchas variables de distinto tipo o cuando buscas interpretabilidad.
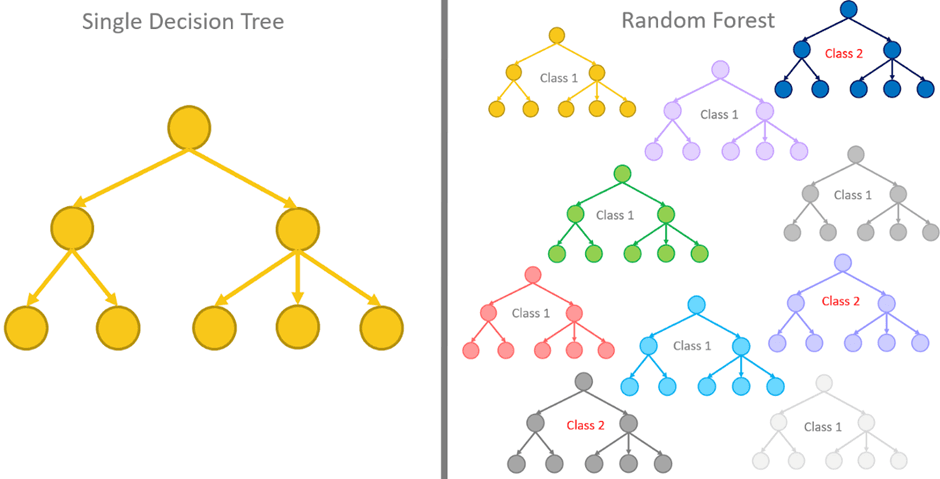
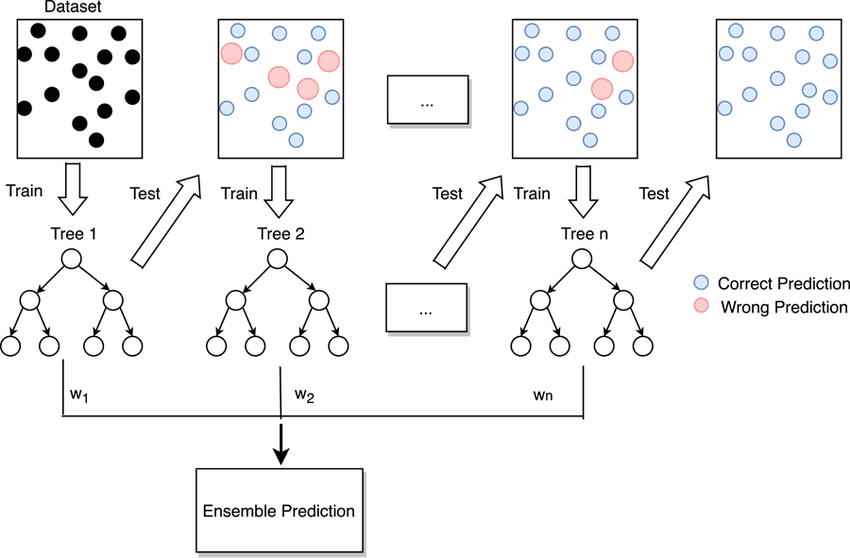
Bosque Aleatorio (Random Forest)
Un bosque aleatorio combina muchos árboles de decisión entrenados sobre muestras diferentes del dataset. La predicción final se obtiene por votación.
Este tipo de modelo suele funcionar bien en la mayoría de problemas de clasificación porque reduce el ruido y el sobreajuste de los árboles individuales.
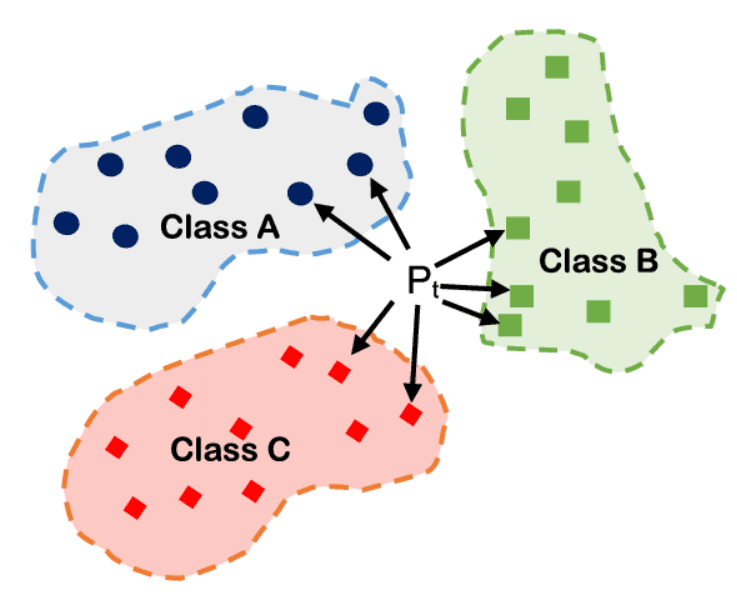
K-Vecinos más Cercanos (KNN)
KNN clasifica una nueva observación mirando cuáles son las más cercanas en el espacio de características. La clase mayoritaria entre esos vecinos decide la predicción.
Es adecuado cuando los datos no siguen una frontera clara y las clases se distribuyen por regiones.
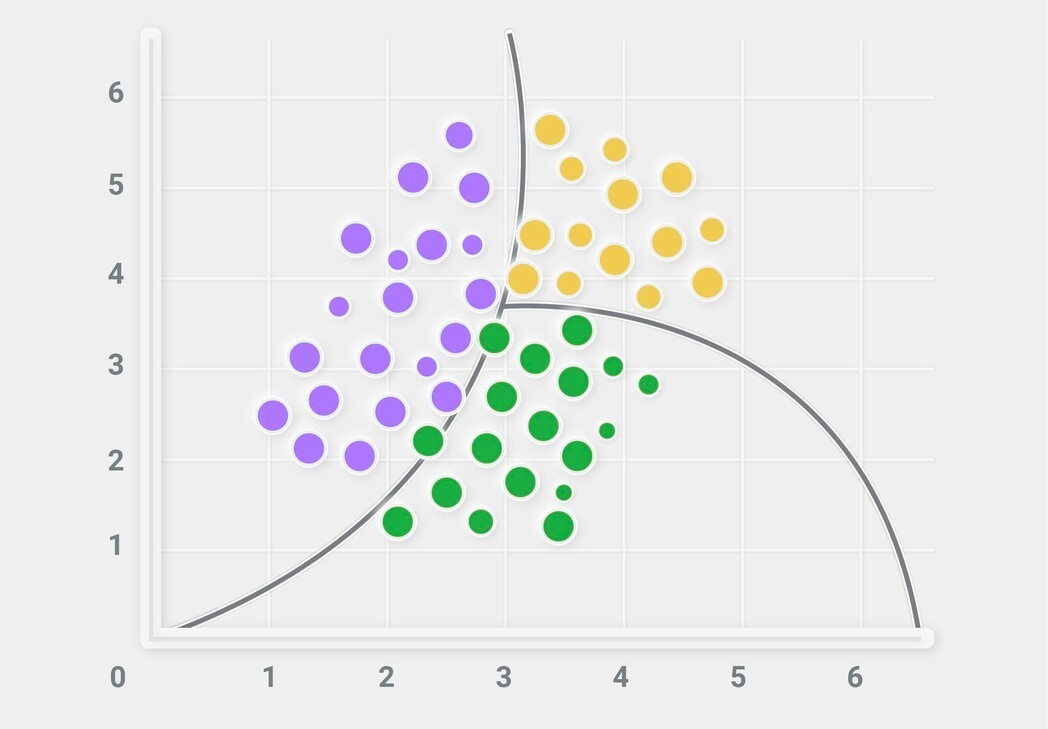
Naive Bayes (NBC)
Naive Bayes es un clasificador probabilístico que asume independencia entre variables.
Funciona especialmente bien en problemas donde las características son frecuentes pero débiles individualmente (por ejemplo, texto, sensores con ruido, frecuencias).
Gradient Boosting Classifier
Modelo basado en ensamble secuencial de árboles, donde cada árbol corrige los errores del anterior.
Es muy eficaz en datasets con relaciones complejas y suele proporcionar alta precisión con una configuración cuidadosa.
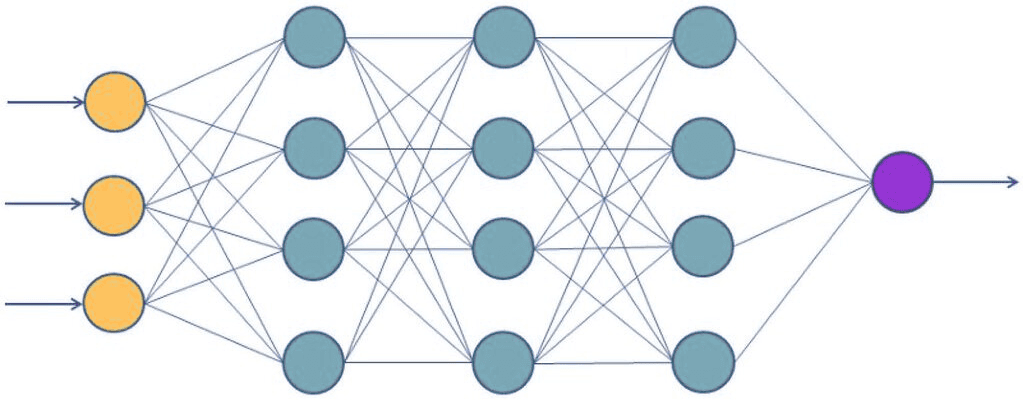
Red Neuronal (MLP Classifier)
Un perceptrón multicapa (MLP) es un modelo basado en capas de neuronas artificiales que aprende relaciones no lineales.
Es adecuado cuando tienes muchas observaciones o cuando los patrones dependen de combinaciones complejas de variables.
Cómo elegir el mejor modelo de clasificación en machine learning - consejos de nuestros expertos
Normaliza los datos cuando uses KNN, regresión logística o redes neuronales.
Balancea las clases si una categoría aparece mucho más que otra; mejora la calidad del modelo.
Empieza con modelos simples (regresión logística, árbol) antes de usar modelos complejos.
Evita los árboles muy profundos para no sobreajustar.
Divide los datos en entrenamiento y test con coherencia temporal si el dataset representa procesos industriales.
No uses todos los hiperparámetros avanzados al principio: ajusta solo los clave según el algoritmo.
Evalúa métricas más allá de la precisión cuando las clases están desbalanceadas (F1, recall).
La clasificación es uno de los algoritmos utilizados para el análisis predictivo sin programación, y aplicar correctamente estas técnicas marca la diferencia entre disponer de datos y obtener valor de ellos.
En IMMERSIA somos especialistas en análisis de datos y visualización avanzada. Si quieres conocer cómo aplicar estas metodologías pueden ayudarte a mejorar tus procesos, aumentar el rendimiento y reducir costes, solicita una DEMO personalizada, y nuestros expertos te guiarán.


