


7 nov 2025
La analítica predictiva consiste en utilizar datos, algoritmos estadísticos avanzados y técnicas de machine learning para anticipar resultados a partir de datos históricos.
La importancia de la analítica predictiva radica en su capacidad para ayudar a las empresas a estimar con precisión qué es lo más probable que ocurra en sus procesos u operaciones. En el ámbito industrial, esto se traduce en anticipar fallos en equipos, reducir el consumo de energía o detectar anomalías en procesos antes de que ocurran.
La analítica predictiva se apoya de forma esencial en el machine learning (ML). Los modelos se entrenan con grandes volúmenes de datos provenientes de sensores y procesos operativos, para reconocer patrones y hacer predicciones cada vez más precisas. Como destaca RT Insights, “los modelos de machine learning se están integrando en los flujos de datos, aprendiendo en tiempo real y ajustando sus predicciones sobre la marcha”.
El enfoque No Code se puede entender como una filosofía digital que permite a los usuarios aprovechar el poder del machine learning para numerosos propósitos sin necesidad de programar. A este enfoque se le conoce también como ‘programación visual’ o ‘programación sin código’ (BBVA).
El análisis predictivo sin código o no-code predictive analytics es posible gracias a plataformas de ML sin código: herramientas que permiten construir, entrenar y desplegar modelos predictivos sin escribir una sola línea de código.
Y aquí está la clave: si quieres aplicar analítica predictiva, ya estás hablando de machine learning. Las plataformas no-code son la forma más rápida y accesible de empezar.
¿Qué es el machine learning sin código?
El machine learning sin código es la capacidad de crear, entrenar y desplegar modelos predictivos a través de interfaces visuales e intuitivas, sin necesidad de programación. En lugar de depender exclusivamente de científicos de datos y programación en lenguajes como Python, estas plataformas democratizan el acceso al aprendizaje automático, facilitando su uso a equipos de operaciones, mantenimiento e innovación.
Estas plataformas simplifican la complejidad técnica con flujos de trabajo de arrastrar y soltar, incluyen motores AutoML que seleccionan y optimizan automáticamente algoritmos, y ofrecen herramientas para validar y visualizar el desempeño de los modelos con solo unos clics. Gracias a esto, el machine learning se vuelve accesible, rápido y escalable, permitiendo que las organizaciones generen insights predictivos a partir de datos brutos y desconectados en días, en lugar de meses.
Este enfoque es especialmente valioso en sectores con grandes volúmenes de datos, como:
¿Cómo funcionan las plataformas no-code de ML?
Las plataformas de machine learning sin código automatizan internamente las tareas técnicas del flujo de trabajo de machine learning como la preparación de datos, la selección de algoritmos o la optimización de modelos, y las traducen a una interfaz visual y guiada para el usuario.
En esencia, encapsulan la complejidad del machine learning en una serie de módulos interconectados. Detrás de cada interacción visual se ejecutan procesos automáticos que normalmente requerirían código y conocimiento especializado.
En el caso de plataformas como TOKII, el funcionamiento general puede entenderse así:
Ingesta y gestión de datos
El usuario conecta sus fuentes de datos, mientras el sistema se encarga de validarlas, limpiar inconsistencias, y sugerir transformaciones necesarias.
Definición del aprendizaje
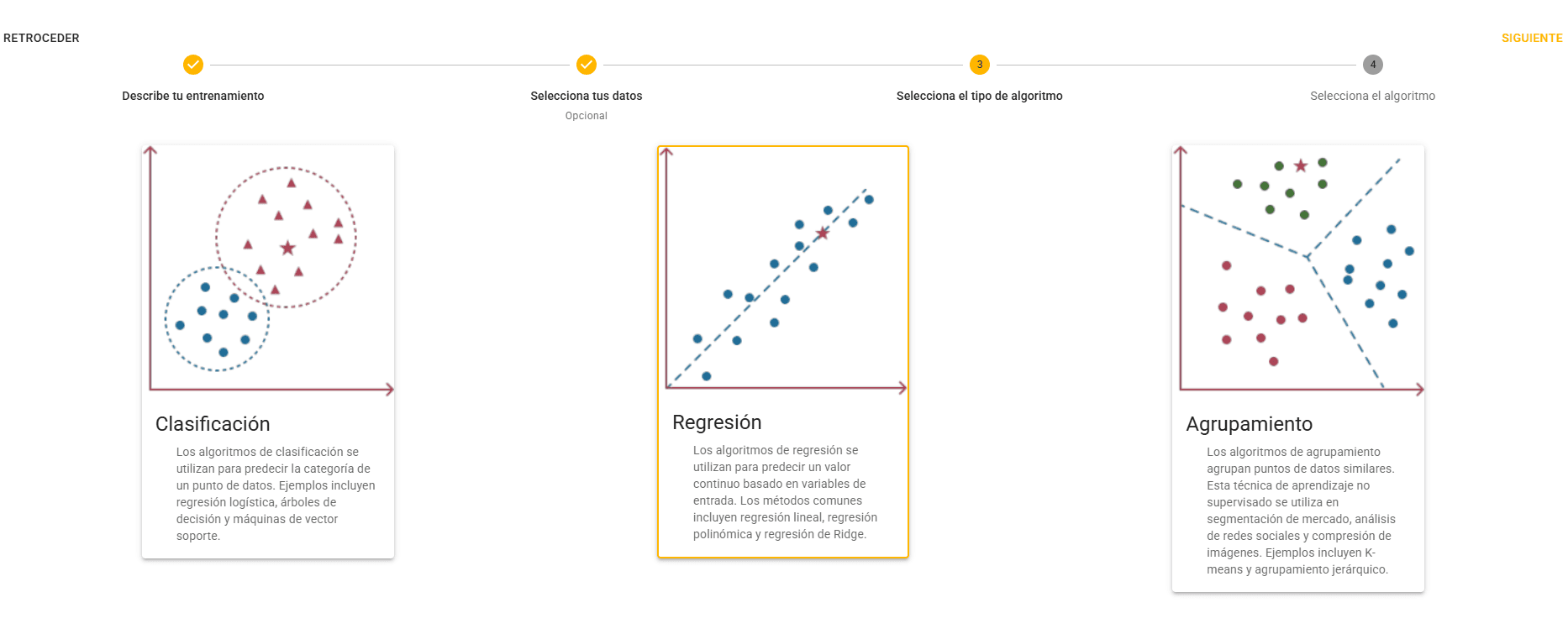
Según el problema, se puede elegir entre aprendizaje supervisado (clasificación o regresión) o no supervisado (clustering).
Selección de algoritmos específicos
La plataforma sugiere o permite elegir entre distintos algoritmos según el problema seleccionado anteriormente: árboles de decisión, bosques aleatorios, redes neuronales, K-Means, entre otros.
Configuración del modelo
Se definen las variables de entrada, la variable objetivo (si aplica), el tamaño del conjunto de prueba y otros parámetros del modelo.
Preprocesamiento de datos
Se pueden aplicar opciones como escalado, codificación de variables categóricas o gestión de valores nulos mediante controles intuitivos.
Entrenamiento y comparación de modelos (nuevas sesiones)
Se lanza el entrenamiento y se pueden crear múltiples sesiones con distintas configuraciones para comparar resultados.
Análisis y evaluación de las métricas del modelo
Una vez entrenado, la plataforma muestra métricas asociadas al tipo de problema elegido como precisión, la matriz de precisión, la curva ROC, R² o número de clústers.
Predicción e interpretación de resultados
El modelo final se aplica a nuevos datasets para generar predicciones, que pueden visualizarse en tiempo real o integrarse en dashboards digitales.
Este enfoque paso a paso permite que equipos de distintos departamentos, desde operaciones hasta estrategia, puedan experimentar, iterar y desplegar modelos predictivos sin escribir código.
Modelos de ML sin código en entornos industriales
Estos son los tres tipos principales de modelos predictivos que puedes crear y desplegar con TOKII, sin necesidad de programar:
1. Modelos de clasificación de datos
Los modelos de clasificación asignan una categoría a cada punto de datos. Son ideales cuando lo que se predice es un resultado discreto.
Detectar anomalías en sensores (“normal” / “crítico”).
Prever estados operativos de maquinaria (“activo”, “en revisión”, “en fallo”).
Clasificar consumos energéticos por niveles (“alto”, “medio”, “bajo”).
Asignar incidencias a un tipo (“eléctrica”, “climatización”, “estructural”).
2. Modelos de regresión
Los modelos de regresión predicen valores numéricos continuos, ideales para estimaciones y proyecciones dinámicas.
Predecir el consumo energético de un edificio en función de variables ambientales.
Estimar la temperatura esperada en un sistema HVAC.
Calcular la producción diaria esperada de una línea de fabricación.
Prever la vida útil restante de un componente.
3. Análisis de clústeres
El clustering es una técnica no supervisada que agrupa datos según similitudes, sin necesidad de etiquetas previas.
Segmentar sensores o equipos según comportamiento similar.
Agrupar patrones de consumo energético por zonas.
Detectar comportamientos atípicos (outliers).
Clasificar activos según rendimiento o mantenimiento histórico.
Beneficios de las plataformas de ML sin código
Para muchas empresas industriales, la principal barrera para aplicar machine learning ha sido la complejidad, no la falta de datos.
Las plataformas sin código eliminan esa barrera, haciendo la IA accesible a ingenieros, analistas y responsables sin necesidad de equipos especializados. Según Fortune Business Insights, “las plataformas de IA sin código reducen drásticamente la necesidad de soluciones especializadas, bajando los costes de desarrollo y facilitando su adopción en todo tipo de industrias”.
Beneficios clave:
Despliegue rápido
De datos a modelo en pocas horas o días.
Menor barrera técnica
No se necesita saber programar. Los expertos en negocio pueden liderar proyectos de IA.
Eficiencia de costes
Se reducen gastos en consultores externos o grandes equipos internos.
Insights escalables
Se puede aplicar en distintas plantas o unidades de negocio.
Valor en tiempo real
Modelos desplegados en dashboards operativos o gemelos digitales para tomar mejores decisiones.
Iteración ágil
Fácil de probar y comparar distintas configuraciones de modelos.
Para las empresas, esto se traduce en menos tiempo de inactividad, mejor asignación de recursos y mayor competitividad.
Con plataformas como TOKII, los equipos industriales pueden construir, entrenar y desplegar modelos de machine learning con unos pocos clics, transformando datos en decisiones en tiempo real sin escribir código.
¿Quieres explorar la analítica predictiva, pero no sabes por dónde empezar? Solicita una demo personalizada de TOKII y deja que nuestro equipo de expertos te guíe paso a paso.


