

La classification est un type de problème d'apprentissage automatique supervisé dans lequel le modèle apprend à attribuer chaque observation à une classe ou catégorie.
Elle sert à déterminer si quelque chose appartient au groupe A ou B (classification binaire) ou à plusieurs catégories possibles (classification multiclasse). L'ensemble de données complet est utilisé pour créer le modèle, et les métriques d'évaluation sont générées à l'aide de la technique de validation croisée, K-fold.
Dans un , elle est utile pour prédire les états des actifs, les conditions opérationnelles, le type de pièce, l'apparition de pannes ou tout scénario où la sortie est une étiquette discrète.
Types de modèles de classification
Généralement, les algorithmes de classification peuvent être regroupés en trois types principaux : binaires, multiclasse et multi-étiquette.
Classification binaire : résout des problèmes avec seulement deux résultats possibles (par exemple, oui/non, réussi/échoué).
Classification multiclasse : sélectionne une étiquette parmi plus de deux catégories.
Classification multi-étiquette : permet d'attribuer plusieurs étiquettes à une même observation simultanément.
Ces distinctions aident à définir comment un modèle de classification est entraîné et évalué, et elles sont essentielles pour choisir l'approche adéquate dans votre processus de développement de l'apprentissage automatique.
Algorithmes de machine learning
Une fois le type de tâche de classification défini, l'étape suivante consiste à sélectionner l'algorithme approprié pour construire le modèle d'apprentissage automatique. Ces algorithmes sont les moteurs mathématiques qui apprennent des données et réalisent des prédictions. Certains des algorithmes inclus dans notre plateforme de jumeaux numériques TOKII sont :
Régression Logistique
La régression logistique est un modèle linéaire qui estime la probabilité qu'un enregistrement appartienne à une classe. Bien que son nom contienne “régression”, il est utilisé exclusivement pour la classification, notamment binaire.
Elle est appropriée lorsque les relations entre les variables et les classes sont relativement simples ou linéaires, ou lorsque l'on souhaite un modèle rapide et stable pour commencer.
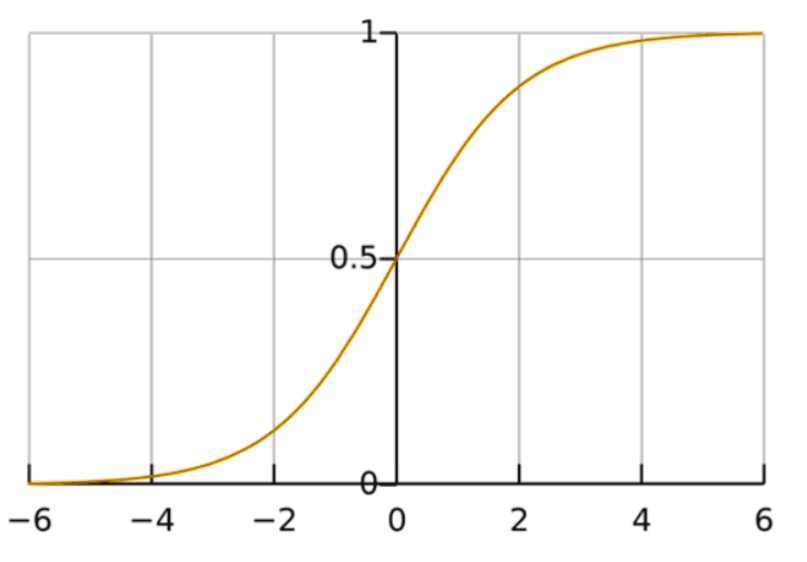
Arbre de Décision
Un arbre divise l'ensemble de données en appliquant des règles du type “si la valeur X est supérieure à Y…”. Il construit une structure de décision qui permet de classer les observations en suivant un parcours de la racine à une feuille.
Elle est utile lorsque vous attendez des relations non linéaires, lorsque vous avez de nombreuses variables de différents types ou lorsque vous recherchez l'interprétabilité.
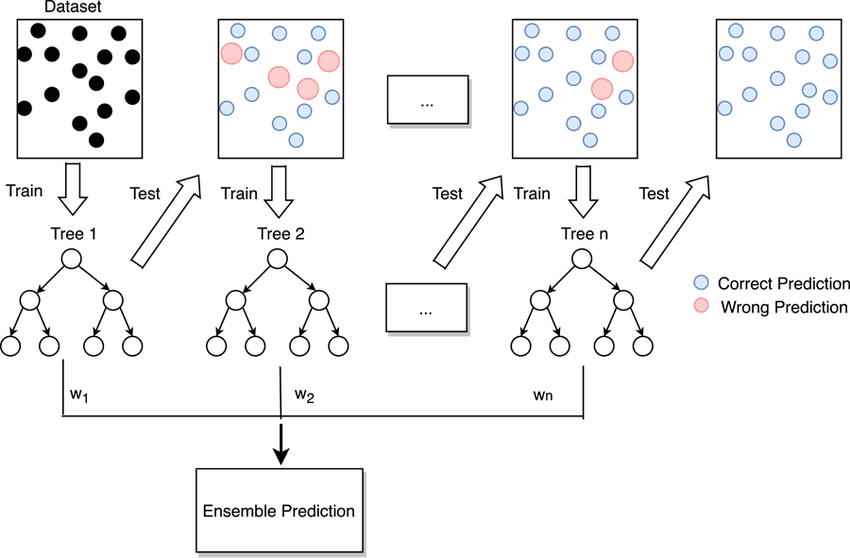
Forêt Aléatoire (Random Forest)
Une forêt aléatoire combine de nombreux arbres de décision entraînés sur des échantillons différents de l'ensemble de données. La prédiction finale est obtenue par le vote.
Ce type de modèle fonctionne généralement bien dans la plupart des problèmes de classification car il réduit le bruit et le surapprentissage des arbres individuels.
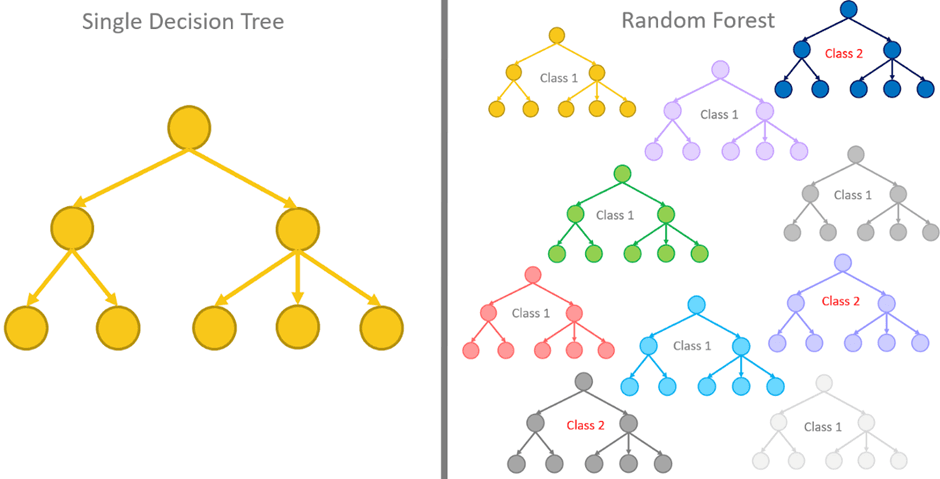
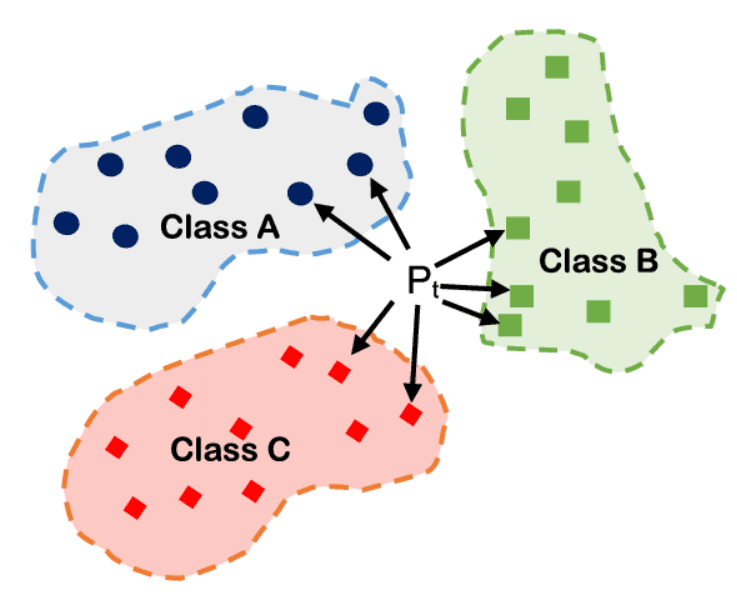
K-Voisins les Plus Proches (KNN)
KNN classifie une nouvelle observation en regardant quelles sont les plus proches dans l'espace des caractéristiques. La classe majoritaire parmi ces voisins décide de la prédiction.
Elle est appropriée lorsque les données ne suivent pas une frontière claire et que les classes se distribuent par régions.
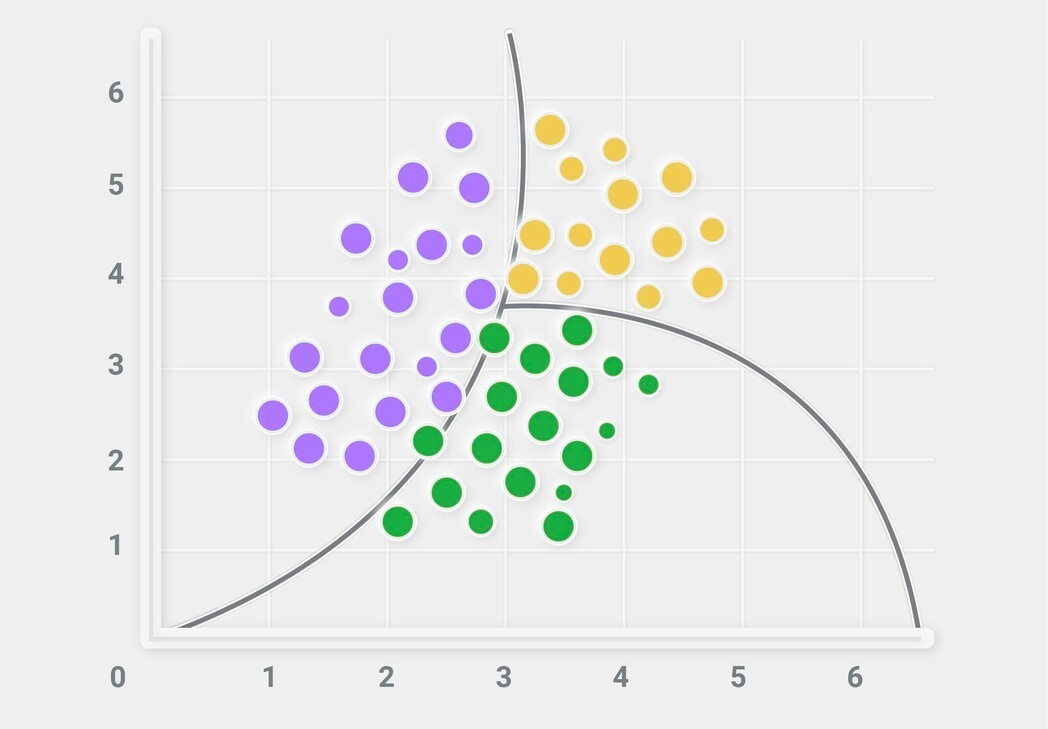
Naive Bayes (NBC)
Naive Bayes est un classificateur probabiliste qui suppose l'indépendance entre les variables.
Il fonctionne particulièrement bien dans les problèmes où les caractéristiques sont fréquentes mais faibles individuellement (par exemple, texte, capteurs avec bruit, fréquences).
Gradient Boosting Classifier
Modèle basé sur l'assemblage séquentiel d'arbres, où chaque arbre corrige les erreurs du précédent.
Il est très efficace sur les ensembles de données avec des relations complexes et fournit généralement une haute précision avec une configuration minutieuse.
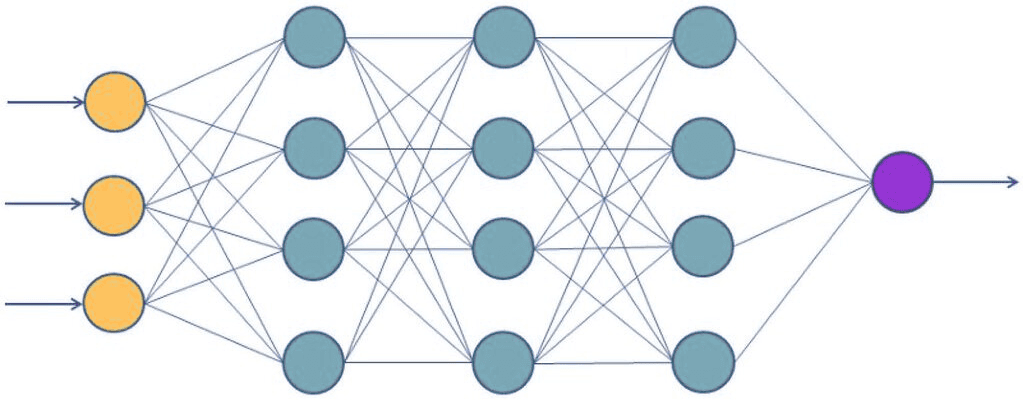
Réseau Neuronal (MLP Classifier)
Un perceptron multicouche (MLP) est un modèle basé sur des couches de neurones artificiels qui apprennent des relations non linéaires.
Elle est appropriée lorsque vous avez de nombreuses observations ou lorsque les modèles dépendent de combinaisons complexes de variables.
Comment choisir le meilleur modèle de classification en machine learning - conseils de nos experts
Normaliser les données lorsque vous utilisez KNN, régression logistique ou réseaux neuronaux.
Équilibrez les classes si une catégorie apparaît beaucoup plus qu'une autre ; améliorez la qualité du modèle.
Commencez par des modèles simples (régression logistique, arbre) avant d'utiliser des modèles complexes.
Évitez les arbres très profonds pour ne pas sur-ajuster.
Divisez les données en formation et test avec cohérence temporelle si l'ensemble de données représente des processus industriels.
N'utilisez pas tous les hyperparamètres avancés au début : ajustez seulement les clés selon l'algorithme.
Évaluez des métriques au-delà de la précision lorsque les classes sont déséquilibrées (F1, rappel).
La classification est l'un des algorithmes utilisés pour l'analyse prédictive sans programmation, et appliquer correctement ces techniques fait la différence entre disposer de données et obtenir de la valeur à partir de celles-ci.
Chez IMMERSIA, nous sommes spécialistes en analyse de données et visualisation avancée. Si vous souhaitez savoir comment appliquer ces méthodologies peut vous aider à améliorer vos processus, augmenter le rendement et réduire les coûts, demandez une DÉMO personnalisée, et nos experts vous guideront.


